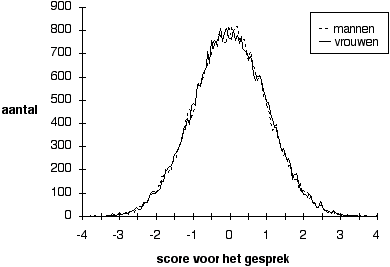
Figuur 5.1 Twee scoreverdelingen zonder partijdigheid,
Noot. 50 % vrouwelijke kandidaten
Het empirische onderzoek heeft inzicht verschaft in de aard en de omstandigheden van de selectieprocedures voor directeuren in het Primair Onderwijs. In het empirisch onderzoek ontbreken gegevens over de kwaliteit van de selectieprocedure: functioneren de zo geselecteerde directeuren echt veel beter dan wanneer er tussen de gekwalificeerde kandidaten alleen zou zijn geloot? Dergelijk onderzoek is niet gemakkelijk uit te voeren, en zou leiden tot het voorspelbare resultaat dat er geen harde conclusies over effecten van deze selectieprocedures zijn te trekken, in het gunstigste geval zou een klein positief rendement aantoonbaar zijn. Op basis van onderzoek dat elders is verricht naar de effecten van selectieprocedures (zie Roe, 1983; Hunter & Hunter, 1984) zijn echter wel analyses te maken over de waarschijnlijke opbrengst van deze selectieprocedures voor directeuren Primair Onderwijs, en ook van bepaalde verbeteringen die daarin zijn aan te brengen. In dit hoofdstuk worden analyses gepresenteerd op de hoofdpunten die ook in de paneldiscussie aan de orde zijn gesteld. Allereerst worden de gevolgen van verschillende denkbare vormen van partijdigheid in beeld gebracht, en wordt bezien hoe deze effecten afhangen van bepaalde omstandigheden die beleidsmatig zijn te beïnvloeden. Bij beleid valt te denken aan betere werving van vrouwen, werken op basis van functieanalyses, het inzetten van specifiek voor deze functie ontwikkelde tests, en het werk van de selectiecommissie vormgeven volgens de methodiek van de selectiepsychologie (richtlijnen NIP, 1985). Maar het gaat niet alleen om partijdigheid, het gaat ook om de opbrengst van de selectieprocedure, en ook die blijkt sterk af te hangen van de kwaliteit van de selectieprocedure.
Het is niet altijd eenvoudig om de effecten van bepaalde selectieprocedures te berekenen, effecten naar partijdigheid, naar het positieve rendement van de procedure ten opzichte van loten, naar de bijdrage die geselecteerden leveren aan het bedrijfsresultaat of aan de kwaliteit van het functioneren van de school. Voeg daaraan toe dat de meeste selectieprocedures bestaan uit een opeenstapeling van activiteiten van een commissie en van een psycholoog, die verschillende instrumenten en informatiebronnen gebruiken, dan klemt de vraag of het wel mogelijk is van partijdigheid een helder en kwantitatief beeld te verkrijgen. Wanneer verschijnselen te ingewikkeld worden om effecten van bepaalde ingrepen langs wiskundige weg te berekenen, en wanneer experimenteel onderzoek naar effecten geen realistische mogelijkheid is, is het soms mogelijk door simulatie de effecten van ingrepen te bestuderen. Dat simuleren hoeft niet altijd de vorm van namaken op kleinere schaal te hebben, het kan ook door een computermodel voor de te bestuderen selectie op te stellen. Ook complexe selectieprocedures laten zich onderzoeken met behulp van simulatie. Uit eerder onderzoek naar de selectie voor de Nederlandse Politie Academie (Wilbrink, Van Hoorn, Van der Kamp en Algera,1990) was al een simulatieprogramma voor complexe selectieprocedures beschikbaar (de methodische onderbouwing hiervoor is afzonderlijk gepubliceerd: Wilbrink, 1990). Dit programma is voor dit onderzoek uitgebreid met de mogelijkheid partijdigheid in te bouwen. Met dit programma is het mogelijk om inzicht te krijgen in verschillen in selectiekansen als gevolg van kleine verschillen tussen mannen en vrouwen in het gemiddelde en/of de spreiding op bijvoorbeeld een intelligentietest. [Het simulatieprogramma is niet in een gebruikersvriendelijke versie beschikbaar. Onderzoekers die met het programma zouden willen werken kunnen contact opnemen: mail
Figuur 5.1 Twee scoreverdelingen zonder partijdigheid,
Noot. 50 % vrouwelijke kandidaten
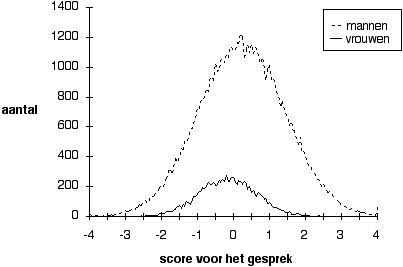
Natuurlijk is het ook voor simuleren nodig om een groot aantal vereenvoudigende veronderstellingen te maken (bijvoorbeeld dat scores op de voorspellers en op het criterium multivariaatnormaal zijn verdeeld; zie voor deze en de andere aannamen in het model: Wilbrink, 1990). Daarom zijn de uitkomsten van een enkele simulatiestudie niet zonder meer zinvol. De techniek voor de simulatiestudies in dit hoofdstuk is dan ook dat uitkomsten van telkens twee of meer simulatiestudies met elkaar worden vergeleken: de vergelijking werkt als een balans waardoor de effecten van de specifieke modelvooronderstellingen links en rechts ongeveer tegen elkaar wegvallen, zodat alleen het verschil tussen wel of geen seksepartijdigheid overblijft. Een grote vereenvoudiging is dat de selectieprocedure wordt beschouwd als opgebouwd uit slechts twee selectie-instrumenten: een commissiegesprek, verder het 'gesprek' te noemen, en een psychologisch onderzoek, verder de 'test' te noemen. Zowel gesprek als test leveren een bepaalde score op. Figuur 1 geeft plot van gesimuleerde scores voor het gesprek van 40.000 mannen en evenveel vrouwen; voor het gemak is het gemiddelde van de scores op nul gezet, en de standaarddeviatie (de spreiding) op 1. In de afgebeelde situatie is er geen partijdigheid: de kleine verschillen tussen beide verdelingen berusten op toevallige fluctuaties. De volgende reeks figuren illustreert wat partijdigheid in het gesprek (of de test) betekent in termen van deze verdelingen van scores.
Wanneer in een selectieprocedure verhoudingsgewijs meer mannen tot de winnaars behoren, dan is die procedure 'partijdig.' Veronderstel dat er evenveel mannen als vrouwen solliciteren, maar dat er twee keer zoveel mannen als vrouwen worden benoemd, dan is het duidelijk dat de selectieprocedure partijdig is ten voordele van mannen. Bij de onderzochte selectieprocedures voor directeuren Primair Onderwijs is de typische verhouding bij de sollicitanten één vrouw op zeven mannen, en noemen we de procedures partijdig wanneer er minder vaak dan één op de acht keer een vrouw wordt benoemd. Dit is een neutrale definitie van wat partijdig is, er is daarmee niets gezegd over de oorzaak van de partijdigheid die best legitiem zou kunnen zijn. In dit hoofdstuk gaat het niet om de vraag welke vormen van partijdigheid legitiem zijn of niet (zie daarvoor Jensen, 1980; Arvey & Faley, 1988; Born, Bleichrodt en Van der Flier,1987; Ashmore, 1990), maar louter om de vraag wat de gevolgen zijn van partijdigheid, en of die gevolgen ook nog afhangen van bijvoorbeeld de omvang van de groep sollicitanten of het aandeel dat vrouwen hebben in de groep sollicitanten.
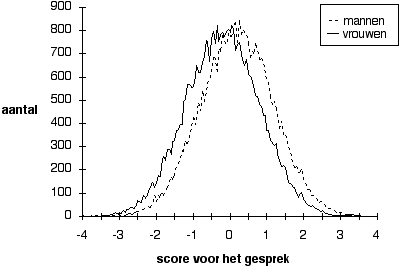
Figuur 5.2 Scoreverdelingen met partijdigheid in gemiddelde
Noot. De partijdigheid is - 0,2 voor alle vrouwen, +0,2 voor alle mannen. Er zijn 50 % vrouwelijke kandidaten.
Figuur 2 laat zien wat het gevolg is van partijdigheid in gemiddeld toegekende scores: beide verdelingen schuiven uit elkaar, wat tot gevolg heeft dat bij selectie van de besten er relatief meer mannen dan vrouwen worden geselecteerd. Wanneer de regel zou zijn dat iedereen met een score van 2 of hoger een baan krijgt aangeboden, laat de figuur zien dat er dan meer mannen dan vrouwen aan die eis voldoen. Deze partijdigheid in gemiddeld toegekende scores zou gecorrigeerd kunnen worden wanneer er normtabellen beschikbaar zijn waarin de gebleken verschillen tussen mannen en vrouwen zijn getabelleerd. De correctie bestaat er eenvoudig uit dat alle scores worden opgehoogd of verlaagd in de mate waarin de twee betrokken groepen gemiddeld afwijken van hun gemeenschappelijke gemiddelde.
De verdelingen in Figuur 2 zijn bedoeld om een beeld te geven van partijdigheid in toegekende scores van mannelijke en vrouwelijke kandidaten ten opzichte van elkaar. De figuur laat een gematigde partijdigheid zien; bij regelrechte discriminatie zouden de verdelingen van mannen en vrouwen zo ver uit elkaar zijn geschoven dat ze alleen nog in de (resp. linker en rechter) uiteinden over elkaar heen vallen. De afgebeelde mate van partijdigheid is zo klein dat bij de veel kleinere aantallen kandidaten van ongeveer 8 in afzonderlijke selectieprocedures de partijdigheid niet meer zichtbaar is te maken. Niet meer zichtbaar betekent evenwel niet dat de partijdigheid dan geen rol meer speelt: zouden voor de mogelijk duizend selectieprocedures die per jaar plaatsvinden voor directeuren Primair Onderwijs de scores worden samengevoegd, dan wordt partijdigheid zichtbaar op dezelfde wijze als in Figuur 2 (maar dan met tien keer zo weinig kandidaten). Er is nog een opmerking bij de situatie in Figuur 2 te maken: de afgebeelde partijdigheid is altijd nog zo klein dat op basis van de behaalde score geen goede 'voorspelling' is te doen of deze score door een man of door een vrouw is behaald. Naarmate de score meer extreem is, valt met een grotere trefkans te zeggen of de betreffende kandidaat een man of een vrouw is. Toch is de hier afgebeelde partijdigheid groot genoeg om te leiden tot soms aanmerkelijk ongunstiger selectiekansen voor vrouwen, zoals de te rapporteren simulaties zullen demonstreren.
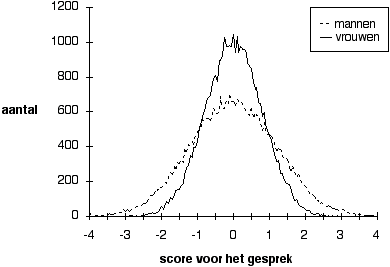
Figuur 5.3 Scoreverdelingen met partijdigheid in spreiding.
Noot. Alle scores van vrouwen zijn met 0,8 zijn vermenigvuldigd, van mannen met 1,2. Er zijn 50 % vrouwelijke kandidaten.
Een minder bekende maar even ernstige vorm van partijdigheid bestaat eruit dat voor de ene groep de scores breder zijn gespreid dan voor de andere. Figuur 3 laat de spreidingspartijdigheid zien welke in de simulatiestudies is gebruikt. Voor de mannen zijn alle scores met 1,2 vermenigvuldigd, voor de vrouwen met 0,8. Het belang van deze vorm van partijdigheid is onmiddellijk uit de figuur af te lezen: wanneer de hoogst scorende kandidaten worden geselecteerd, worden in deze situatie veel meer mannen dan vrouwen geselecteerd. De ongelijkheid wordt groter naarmate de selectie scherper is, dat wil zeggen naarmate de grenslijn voor de selectie in de figuur opschuift van score 1 naar 2, en verder naar 3.
Deze vorm van partijdigheid kan ontstaan wanneer beoordelaars met de ene groep kandidaten meer vertrouwd zijn dan met de andere: binnen de vertrouwde groep ziet men makkelijker verschillen, in de minder vertrouwde groep worden oordelen gegeven die dichter bij het gemiddelde blijven. Recent heeft Feingold (1992) in een uitvoerige studie een poging gedaan dergelijke effecten te schatten op basis van eerder empirisch onderzoek; dit artikel heeft geleid tot een serie replieken en duplieken. Hedges en Friedman (1993, p. 102) laten zien hoe effecten van partijdigheid in gemiddelden en in spreiding wiskundig zijn te berekenen. Door te simuleren zijn deze wiskundige analyses overbodig en kunnen zonder meer succeskansen voor mannen en voor vrouwen worden gegenereerd.
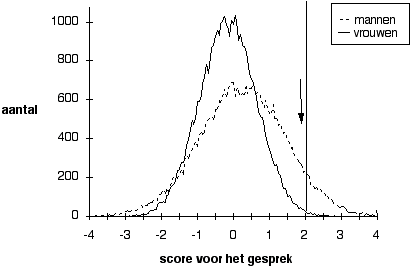
Figuur 5.4 Scoreverdelingen met partijdigheid in zowel gemiddelde als spreiding
Noot. Partijdigheid in gemiddelden: 0,2 afgetrokken of opgeteld ; in spreiding: met 0,8 of 1,2 vermenigvuldigd. Er zijn 50 % vrouwelijke kandidaten.
Als er in de wereld sprake is van partijdigheid, dan zal dat een mengvorm zijn van partijdigheid in gemiddelde en in spreiding. Figuur 4 laat de combinatie zien van de eerder in Figuur 2 en 3 afgebeelde partijdigheid. Er is nu aan de rechterzijde van de figuur een nog sterker oververtegenwoordiging van mannen. Wanneer selectie van alleen degenen met een score hoger dan 2 plaats zou vinden, vallen de kandidaten rechts van de ingetekende pijl in de prijzen, en daar is maar een enkele vrouw bij. Maar omdat het niet gaat om een enkele mega-selectieprocedure waaraan 80.000 kandidaten deelnemen, dat is een orde van grootte zoals in het oude China bij de provinciale examens voorkwam, is wat door de pijl wordt afgesneden geen goede weergave van de situatie van selectie van directeuren. De volgende figuur geeft wel een goed beeld van de uitkomst bij 10.000 afzonderlijke selectieprocedures.
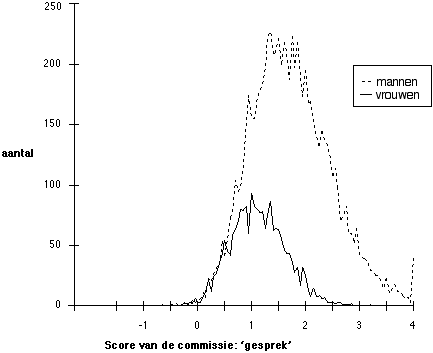
Figuur 5.5 Partijdigheid bij 10.000 'benoemingen' op basis van scores voor het 'gesprek' zoals afgebeeld in Figuur 4
Noot. Partijdigheid in gemiddelden: 0,2 afgetrokken of opgeteld ; in spreiding: met 0,8 of 1,2 vermenigvuldigd. Er zijn 50 % vrouwelijke kandidaten.
Liet Figuur 4 nog zien dat bij een megaselectie in één enkele procedure van 80.000 kandidaten er bij partijdigheid in de scores maar een enkele vrouw tot directeur zou worden benoemd, in Figuur 5 blijken de gevolgen voor vrouwen afgezwakt te zijn wanneer rekening wordt gehouden met de werkelijkheid dat de selectie van 10.000 directeuren in evenzovele afzonderlijke procedures plaatsvindt. In een procedure met acht kandidaten kan het gebeuren dat een kandidaat met een heel goede score nog wordt overtroffen door iemand anders. Een andersom, dat een kandidaat met een matige score daarmee de overigen toch de loef afsteekt. Daarom zijn er in Figuur 5 nogal wat kandidaten met matige scores die toch zijn 'benoemd,' en zijn er heel wat hoog scorende kandidaten die niet bij de selectie voorkomen omdat zij door nog hoger scorenden zijn overtroefd. Wat de vergelijking van Figuur 4 met Figuur 5 leert is dat effecten van partijdigheid worden afgezwakt naarmate het aantal kandidaten per afzonderlijke selectieprocedure kleiner is. [In het volgende zijn ook enkele simulaties gerapporteerd waar de selectieverhouding 1 op 80 is, in plaats van 1 op 8: dan zijn de effecten van partijdigheid ook meer extreem.] Omdat enkele tientallen scores hoger dan 4 zijn afgerond tot 4, gaat de lijn in de verdeling van mannen uiterst rechts nog even omhoog.
Figuur 5.6 Scoreverdelingen met partijdigheid in zowel gemiddelde als spreiding
Noot. Partijdigheid in gemiddelden: 0,2 afgetrokken of opgeteld ; in spreiding: met 0,8 of 1,2 vermenigvuldigd. Er zijn 12,5 % vrouwelijke kandidaten.
De simulatie is herhaald voor de dichter bij de huidige praktijk staande situatie dat er op iedere acht kandidaten maar één vrouw is: Figuur 6 en 7 geven daarvan de resultaten: maar 3 % van de winnaars is vrouw, terwijl er 12,5 % in het aanbod voorkwamen.
Voor de in Figuur 5 en 7 afgebeelde simulatie is uitgegaan van de situatie waarin alleen op het 'gesprek' wordt geselecteerd, er telkens acht kandidaten zijn, en de partijdigheid in gemiddelde en spreiding de omvang heeft zoals in Figuur 4 is afgebeeld. Bij 80.000 kandidaten zijn er 10.000 selectieprocedures. Dat is een heel erg groot aantal, ook vergeleken met de ongeveer 800 procedures die jaarlijks in Nederland plaatsvinden. Er worden voor de simulatie zo groot mogelijke aantallen gebruikt om daardoor makkelijker door de toevalsfluctuaties heen de systematische effecten zichtbaar te kunnen maken. Let wel, door van grotere aantallen uit te gaan worden effecten niet groter, alleen beter zichtbaar: grotere aantallen leveren geen vertekend beeld van de werkelijkheid op, wel een scherper beeld.
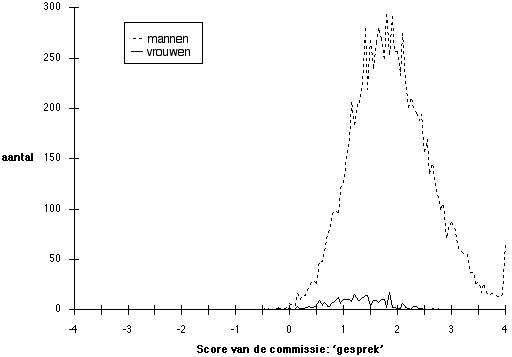
Figuur 5.7 Partijdigheid bij 10.000 'benoemingen' op basis van scores voor het 'gesprek' zoals afgebeeld in Figuur 6
Noot. Partijdigheid in gemiddelden: 0,2 afgetrokken of opgeteld ; in spreiding: met 0,8 of 1,2 vermenigvuldigd. Er zijn 12,5 % vrouwelijke kandidaten, van de benoemingen is 3 % vrouw.
De kwaliteit van selectie-instrumenten wordt vrijwel volledig bepaald door hun voorspellende geldigheid: dat is de mate waarin gesprek of test in staat zijn toekomstig functioneren goed te voorspellen. Immers, hoe beter de voorspelling, des te groter de kans dat die kandidaten worden geselecteerd die als directeur het beste voldoen. Selectie-instrumenten mogen niet partijdig zijn; voorzover deelgroepen verschillend scoren horen daar normtabellen per deelgroep voor te zijn, zodat voor dergelijke verschillen kan worden gecorrigeerd. Voor het simuleren van selectie gaat het uitsluitend om de predictieve geldigheid van gesprek en test. In de verdere uitwerking van de simulatiestudie zal nog blijken dat er externe omstandigheden zijn die mede bepalen wat het rendement is dat met overigens geldige selectie-instrumenten is binnen te halen: het aantal kandidaten is belangrijk, de verhouding mannen - vrouwen in het aanbod, en ook de volgorde waarin instrumenten worden ingezet.
De voorspellende geldigheid van een test wordt uitgedrukt als correlatie-coëfficiënt tussen testscores en de beoordeling van de kwaliteit van de uitoefening van de functie. Tussen test en beoordeling ligt een behoorlijke tijdsspanne, omdat de functionaris zich behoorlijk ingewerkt moet kunnen hebben; te denken valt aan minstens een jaar. In beginsel moeten er voor het bepalen van de voorspellende geldigheid empirische gegevens worden verzameld. Voor deze simulatiestudie kan worden volstaan met te veronderstellen dat de predictieve geldigheid van de instrumenten bekend is. De score die de beoordeling van het functioneren oplevert wordt hier, in overeenstemming met de selectiepsychologische literatuur, criteriumscore genoemd, ook wel kortweg het criterium. De vrijheid gaat niet zo ver dat ieder willekeurig getal een goed uitgangspunt voor simulatie is. Voor het typische selectiegesprek is bekend dat de voorspellende geldigheid daarvan erg laag is, en wel 0,1 of een fractie beter. Voor het psychologisch onderzoek is de voorspellende geldigheid ook niet hoog, maar toch een belangrijk stuk beter dan die van het gesprek: een waarde van 0,3 is voor de te onderzoeken procedure realistisch. Dit zijn bepaald geen hoge voorspellende waarden, maar bedacht moet worden dat de selectie van directeuren Primair Onderwijs gebeurt zonder behoorlijke functieanalyses als basis, zonder instrumenten die specifiek voor deze selectie zijn ontwikkeld, en met commissies die veelal professionele deskundigheid (van de psychologische methodiek, NIP 1988) voor selectie ontberen. Ook is er gewoon geen empirisch onderzoek gedaan naar voorspellende geldigheden, en dan is er geen reden om op voorhand al optimistische waarden te kiezen. Voor een overzicht van wat (Amerikaans) onderzoek over de voorspellende geldigheid van psychologische tests heeft opgeleverd, zie Hunter & Hunter (1984). Voor selectie waarbij zowel een gesprek als een test worden gebruikt, is ook de correlatie tussen beide instrumenten nodig om te kunnen simuleren. Over dergelijke correlaties valt op basis van empirisch onderzoek weinig te zeggen, Hunter en Hunter doen daar bijvoorbeeld geen uitspraken over. Voor de simulaties wordt daarom voor de correlatie tussen beide instrumenten aangenomen dat deze gelijk is aan de laagste van de voorspellende geldigheden. Zie Tabel 1 voor het volledige beeld van de uitgangssituatie voor de simulatiestudie. [Alle correlaties en voorspellende geldigheden zijn waarden zoals deze gelden voor de nog ongeselecteerde groep kandidaten. Er is geen sprake van door restriction of range gekrompen waarden. Criteriumscores zijn verondersteld te zijn gecorrigeerd voor onbetrouwbaarheid.]
Tabel 5.1
Correlatiematrix van instrumenten en criterium
| gesprek | test | |
| test | 0,1 | - |
| criterium | 0,1 | 0,3 |
Het criterium is erg belangrijk: tenslotte is de hele selectie gericht op het vinden van de beste kandidaat, dat is de kandidaat die de hoogste verwachte bijdrage aan het bedrijfsresultaat levert, of de directeur die op cruciale aspecten zijn of haar functie het best uitvoert en inhoud geeft. Bij de bespreking van de simulaties zal verder worden ingegaan op het criterium, omdat dan ook aan de orde is in hoeverre verbeteringen in de procedure effect hebben op het criterium. Als schaal voor de criteriumscores is dezelfde schaal gekozen als voor de instrumenten: gemiddelde nul, en spreiding één. Het gemiddelde nul mag worden geïnterpreteerd als de opbrengst van een procedure waarin wordt geloot. Het gebruik van instrumenten is alleen zinvol wanneer dat resulteert in criteriumscores die beter zijn dan wat bij loten wordt verkregen. [Preciezer: criteriumscores die zoveel hoger uitvallen dat tenminste de kosten van het (inzetten van het) instrument worden terugverdiend.]
De selectie van directeuren Primair Onderwijs gebeurt typisch door eerst een gesprek te voeren met 8 kandidaten waarvan er één een vrouw is, daaruit de 'beste' kandidaat door te sturen voor psychologisch onderzoek (wanneer psychologisch onderzoek deel uitmaakt van de procedure), waarna de commissie, gezien het rapport van de psycholoog, een eindoordeel velt. Voor de simulatiestudies wordt aangenomen dat de commissie telkens twee van de kandidaten doorstuurt voor psychologisch onderzoek, waarna de beslissing valt op basis van een gelijke weging van zowel de score uit het gespek als die uit het psychologisch onderzoek (de 'test').
De techniek van het simuleren is elders beschreven (Wilbrink, 1990). Hier is het alleen van belang op te merken dat de voorspellende geldigheden in Tabel 1 opgesomd, en de werkwijze zoals in de voorgaande alinea aangegeven, de selectieprocedure volledig kenmerken. De techniek van de simulatie berust uitsluitend op deze kenmerken, en geen andere: scores van individuele kandidaten worden zo gegenereerd dat wanneer daarover de correlaties tussen instrumentenscores en criteriumscores berekend zouden worden, de ingevoerde correlaties (zoals in Tabel 1) gereproduceerd worden (op toevalsfluctuaties na). [De veronderstelling is dat scores op instrumenten en criterium multivariaat-normaalverdeeld zijn. De normaalverdeling was al in Figuur 1 te herkennen. Als generator van de benodigde random getallen is de procedure Ran3 gebruikt uit Press, Flannery, Teukolsky & Vetterling, 1986.] Voor de simulatie van partijdigheid worden deelgroepen onderscheiden, waarvoor in deze studie mannen en vrouwen worden genomen. Omdat partijdigheid inhoudt dat de verdelingen van scores voor mannen kunnen verschillen van die van vrouwen, ook wanneer voorspellende geldigheden voor beide groepen identiek zijn, wordt in de simulatiestudies rekening gehouden met deze verschillen in verdelingen, voor deze studie beperkt tot verschillen in gemiddelde en in spreiding. De eerder gepresenteerde figuren zijn gebaseerd op deze gesimuleerde verdelingen.
Nu in het voorgaande het begrip 'partijdigheid' duidelijk is gemaakt in het geval van scores voor alleen het gesprek, en in de voorgaande paragraaf de systematiek van het simuleren van een selectieprocedure met zowel een gesprek als een test is aangegeven, kunnen nu de resultaten van het simuleren van de selectieprocedure worden besproken. In de volgende figuren komt telkens dezelfde opzet terug: de resultaten worden afgebeeld voor verschillende verhoudingen mannen - vrouwen in de groep kandidaten, en voor 6 varianten van partijdigheid. Hoe de verhouding mannen - vrouwen in de groep sollicitanten ook is, de veronderstelling is dat vrouwen en mannen gelijk zijn gekwalificeerd (preciezer: dat de verdeling van kwalificaties voor mannen gelijk is aan die voor vrouwen). Voor de varianten van partijdigheid is gekozen voor telkens enkelvoudige partijdigheid van ofwel spreiding ofwel gemiddelde, op ofwel gesprek ofwel test. Ter vergelijking worden telkens ook de resultaten gegeven wanneer er geen partijdigheid is (de eenvoudige kruisjes), en een situatie van maximale partijdigheid waarin gesprek en test beide zowel naar gemiddelde als naar spreiding partijdig zijn (kruisjes met streepje). De mate van partijdigheid is altijd zoals eerder al aangegeven: +/- 0,2 naar gemiddelde, en +/- 0,2 naar spreiding (d.w.z.: de scores van mannen vermenigvuldigd met 1,2, die van vrouwen met 0,8). De reden voor deze keuze is alleen dat deze mate van partijdigheid relatief bescheiden is, en toch belangrijke invloed op de kansen voor de benadeelde groep heeft. Er is altijd gekozen voor partijdigheid ten nadele van vrouwen, om de voorbeelden concreet te houden; in werkelijkheid kan partijdigheid natuurlijk ook wel eens gunstig voor vrouwen uitwerken, hier wordt dus niet gesuggereerd dat àls er partijdigheid is, die dan ook altijd ongunstig voor vrouwen zou uitwerken. De simulaties zijn gedaan met telkens 10.000 selectieprocedures, tenzij anders aangegeven (er zijn enkele series van 100.000 gedaan). In Figuur 8 zijn de resultaten samengevat van 7 (aantal verschillende verhoudingen mannen - vrouwen) maal 6 (varianten van partijdigheid) maal 100.000 is totaal 4.200.000 selectieprocedures, met per procedure 8 kandidaten, in totaal 33.600.000 kandidaten. [Voor de simulatie zoals afgebeeld in Figuur 8 heeft de Macintosh IIsi met floating-point unit ongeveer 6 uur nodig.]
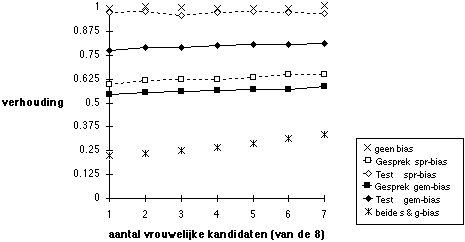
Figuur 5.8 Succeskans vrouwen t.o.v. mannen
Noot. Gesprek (voorspellende geldigheid 0,1) selecteert 2 uit 8, dan beslissing op basis van test (voorspellende geldigheid 0,3) en gesprek samen;100.000 keer.
Figuur 8 geeft de uitgangssituatie weer: er zijn grote effecten van partijdigheid bij het gesprek, zowel partijdigheid in gemiddelde als in spreiding: de kansen kunnen makkelijk dalen tot de helft van die voor mannen. Merk op dat het effect van een kleine mate van partijdigheid als het ware wordt vergroot door de selectieverhouding van één kandidaat van de acht die de baan krijgt. Geringe partijdigheid bij het gesprek leidt al tot verhoudingsgewijs veel sterkere reductie van kansen voor de benadeelde partij. In deze situatie heeft partijdigheid in het gemiddelde van de test, die pas na de eerste selectie op basis van het gesprek wordt afgenomen, toch ook nog een niet te verwaarlozen effect: een reductie tot 0,8 t.o.v. mannelijke kandidaten. Stapeling van effecten brengt de vrouwen in een nog nadeliger positie: kansen tot wel een vijfde van die voor mannen. Merk op dat de verhouding mannen - vrouwen in de groep kandidaten vrijwel geen verschil maakt: er is een miniem effect van de aanwezigheid van relatief meer vrouwen onder de kandidaten: dan is er een fractie minder nadeel.
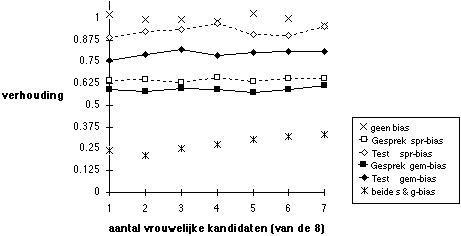
Figuur 5.9 Succeskans vrouwen t.o.v. mannen, bij verhoogde voorspellende geldigheid: gesprek 0,3; test 0,5
Noot. Gesprek selecteert 2 uit 8, dan beslissing op basis van test en gesprek samen.
De voorspellende geldigheid van gesprek en test voor de simulatie in Figuur 8 zijn resp. 0,1 en 0,3. De simulatie is ook gedaan voor de relatief veel hogere voorspellende geldigheden van resp. 0,3 en 0,5, met (op toevalsfluctuaties na) dezelfde resultaten, zie Figuur 9. De uitkomsten in Figuur 9 zien er grilliger uit dan die in Figuur 8, zij zijn dan ook telkens gebaseerd op 10.000 procedures, in plaats van de 100.000 in Figuur 8. Dat de uitkomsten niet verschillen van die in Figuur 8 is een belangrijk resultaat, dat overigens in de literatuur (Jensen, 1980) ook bekend is: verschillen in voorspellende geldigheid hebben op zich geen effect op de gevolgen van eventuele partijdigheid in de instrumenten. Dat het toch van groot belang is de voorspellende geldigheid van de instrumenten en van de procedure te verhogen, volgt nog uit hierna te rapporteren resultaten over de gemiddelde criteriumscores van geselecteerde kandidaten. De problematiek van gelijke kansen voor gelijkwaardige groepen moet dus worden onderscheiden van de vraag hoe het rendement van de selectieprocedure kan worden verbeterd.
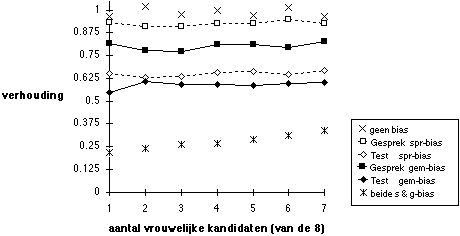
Figuur 5.10 Succeskans vrouwen t.o.v. mannen: gesprek NA test
Noot. Test (voorspellende geldigheid 0,5) selecteert 2 uit 8, dan beslissing op basis van gesprek (voorspellende geldigheid 0,3) en test samen.
De voorspellende geldigheid van gesprek en test is nogal ongelijk: het gesprek heeft veel minder voorspellende waarde dan de test. Toch is in de meeste selectieprocedures de volgorde: eerst selectie door het gesprek, daarna een test, en een eindbeslissing waarin test en gesprek beide meewegen. In deze procedure krijgt het gesprek een relatief groot gewicht, terwijl het de slechtste voorspeller is. Het ligt dan voor de hand om te onderzoeken wat de gevolgen zijn wanneer de volgorde wordt omgedraaid, wanneer het gesprek NA de test komt. Deze volgorde is gesimuleerd met als regel dat op basis van testscores de twee beste kandidaten doorgaan voor het gesprek, waarna de gecombineerde score op test en gesprek bepalend is voor wie de vacature mag gaan vervullen. Figuur 10 laat de simulatieresultaten zien. De ongelijke kansen zijn onveranderd ten opzichte van de situatie waarin het gesprek als eerste selectiedrempel wordt benut. Dit resultaat was ook te verwachten, omdat de omkering in de volgorde de voorspellende geldigheid van de selectieprocedure in zijn geheel verbetert, en verbeterde validiteit geen dempende werking heeft op de gevolgen van partijdigheid zoals eerder gedemonstreerd. Later zal nog blijken hoe de verhoogde voorspellende geldigheid bij deze volgorde van test en gesprek het rendement van de selectieprocedure verbetert.
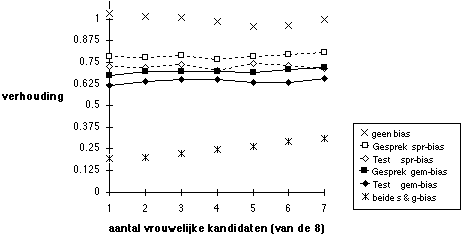
Figuur 5.11 Succeskans vrouwen t.o.v. mannen
Noot. Test (voorspellende geldigheid 0,5) selecteert 4 uit 8, dan beslissing op basis van gesprek (voorspellende geldigheid 0,3) en test samen. 100.000 keer.
Zelfs een eenvoudige selectieprocedure met twee selectiefasen is niet altijd overzichtelijk in zijn uitwerking. Wanneer de test voor de eerste selectie wordt gebruikt, en er niet twee, maar vier van de acht kandidaten door mogen gaan voor het gesprek, veranderen de effecten van partijdigheid op niet makkelijk na te voelen wijze: vergelijk Figuur 11 met Figuur 10. Partijdigheid in de spreiding van de testscores heeft in de eerste fase geen uitwerking omdat immers precies de helft van de kandidaten hier wordt doorgelaten. Zie Figuur 3 waarin de situatie met partijdigheid in spreiding is afgebeeld: wanneer kandidaten met een score nul of beter worden doorgelaten zijn dat evenveel mannen als vrouwen. Toch benadeelt deze partijdigheid vrouwen, omdat de testscore ook nog een rol speelt bij de eindafweging waarbij immers scores voor gesprek en test worden opgeteld. De simulatieresultaten zijn ook teleurstellend voor wie mocht verwachten dat het doorlaten van vier in plaats van twee kandidaten op basis van testscores met partijdigheid leidt tot demping van de effecten van deze partijdigheid. Het is juist voor de analyse van dergelijke ingrepen in de opzet van een selectieprocedure dat het gebruikte simulatieprogramma uitsluitsel kan geven over de richting van de effecten, en of er eigenlijk wel effecten zijn. Overigens geldt ook hier de waarschuwing dat uitblijven van effecten op de kansen van vrouwen de mogelijkheid nog open laat dat dit type verandering tot een verhoogd rendement van de selectieprocedure kan leiden.
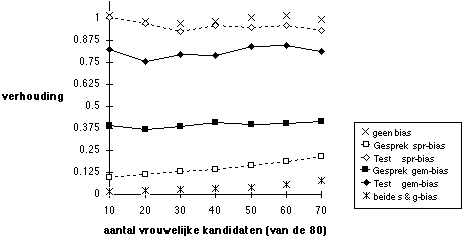
Figuur 5.12 Succeskans vrouwen t.o.v. mannen onder de scherpe selectieverhouding van 1 op 80.
Noot. gesprek (voorspellende geldigheid 0,1) selecteert 2 uit 80, dan beslissing op basis van test (voorspellende geldigheid 0,3) en gesprek samen.
Bij partijdigheid is het erg belangrijk wat de selectieverhouding is: hoe scherper er wordt geselecteerd, des te scherper ook zijn de effecten van eventuele partijdigheid. Figuur 12 geeft de resultaten van dezelfde selectieprocedure als afgebeeld in Figuur 8, maar nu is de selectieverhouding één op tachtig, in plaats van één op acht. Bij dergelijke scherpe selectieverhoudingen kan geringe partijdigheid snel leiden tot ernstige ondervertegenwoordiging van de benadeelde groep onder de winnaars. De figuur laat ook zien dat de effecten van partijdigheid in spreiding sneller stijgen bij toenemende scherpte van de selectie dan die van partijdigheid in gemiddelden.
Bij de selectie van directeuren Primair Onderwijs kan er sprake zijn van scherpe selectieverhoudingen wanneer er veel gekwalificeerde sollicitanten zijn. Omdat de brievenselectie ook kan worden beïnvloed door partijdigheid, verdient de veelal gevolgde strategie om zoveel mogelijk vrouwen voor een gesprek op te roepen zeker aanbeveling, maar deze kan de nadelige effecten van een scherpe selectieverhouding maar gedeeltelijk wegnemen. Immers, de scherpe selectie van mannen in een situatie van partijdigheid blijft ertoe leiden dat mannen het te makkelijk van vrouwen winnen. Een vergelijkbare situatie is eerder geanalyseerd: in de eerste selectiefase minder scherp selecteren leidt niet tot merkbare afzwakking van effecten van partijdigheid in die eerste fase (zie Figuur 11 en de toelichting daarop).
De volgorde van eerst de test en daarna het gesprek laat effecten zien die in dezelfde orde van grootte liggen, en daarom hier niet zijn afgebeeld. Verschillen in voorspellende geldigheid van de test of het gesprek leiden ook hier niet tot verschillen in de effecten van partijdigheid.
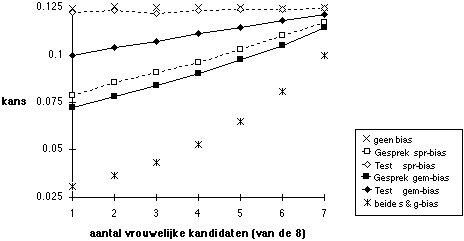
Figuur 5.13 Succeskans voor vrouwen: een partijdige afbeelding
Noot. gesprek (voorspellende geldigheid 0,1) selecteert 2 uit 8, dan beslissing op basis van test (voorspellende geldigheid 0,3) en gesprek samen;100.000 keer.
Wanneer het aandeel van vrouwen in de groep kandidaten stijgt, merken individuele vrouwen minder van de eventueel aanwezige partijdigheid: de kansen op succes nemen dan toe, zie Figuur 13. Wat de figuur niet laat zien is dat de kansen van mannen eveneens stijgen naarmate er relatief meer vrouwen zijn. Figuur 13 geeft daarom een vertekend beeld, een partijdige afbeelding, van het effect van vergrote deelname van vrouwen in sollicitatieprocedures: de werkelijkheid is dat de kansen van vrouwen ten opzichte van die van mannen, zoals in Figuur 8 getoond, vrijwel gelijk blijven. Partijdigheid blijft dus even schadelijk voor de benadeelde partij, ongeachte de verhoudig mannen - vrouwen in de groep van sollicitanten. Wanneer er twee groepen zijn die ten opzichte van elkaar partijdig worden behandeld, dan is iedere presentatie van uitkomsten waarin één van beide partijen afwezig is, een partijdige afbeelding. Op basis van alleen de succeskansen van vrouwen mag niet de conclusie worden getrokken dat zorgen voor een groter deel vrouwen onder de sollicitanten kan leiden tot vermindering van partijdigheid: de eventuele partijdigheid in gesprek of test verandert daardoor niet, en de effecten ervan blijven wezenlijk dezelfde (Figuur 8). Ook wanneer alleen naar de proportie vrouwen onder de winnaars wordt gekeken is er sprake van eenzijdige analyse, zie Figuur 14.
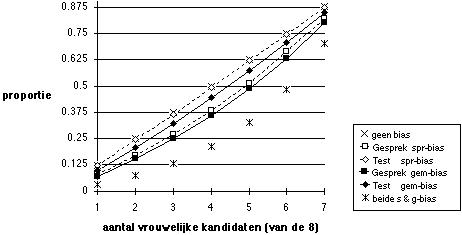
Figuur 5.14 Proportie vrouwelijke winnaars: ook een partijdige afbeelding
Noot. Gesprek (voorspellende geldigheid 0,1) selecteert 2 uit 8, dan beslissing op basis van test (voorspellende geldigheid 0,3) en gesprek samen;100.000 keer.
Wanneer partijdigheid leidt tot ongelijke kansen voor vrouwen, is het effect daarvan dat vrouwen ondervertegenwoordigd zijn in de benoemingen. Figuur 14 laat zien hoe sterk dat effect is bij verschillende verhoudingen mannen - vrouwen in het aanbod: naarmate er minder vrouwen in het aanbod zijn, is de ondervertegenwoordiging bij de winnaars sterker. Dit is geen opzienbarend resultaat, omdat in de situatie waarin er uitsluitend vrouwen solliciteren ook geen ondervertegenwoordiging van vrouwen kan optreden: naarmate mannen de plaats van vrouwen innemen, ontstaat er meer ruimte voor het optreden van partijdigheidseffecten. Figuur 15 laat dat effect beter zien, voor een scherpere selectieverhouding.
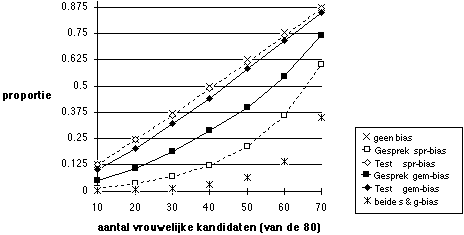
Figuur 5.15 Proportie vrouwelijke winnaars, selectieverhouding 1 op 80
Noot. Gesprek (voorspellende geldigheid 0,1) selecteert 2 uit 80, dan beslissing op basis van test (voorspellende geldigheid 0,3) en gesprek samen.
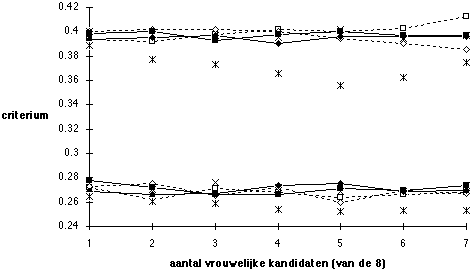
Figuur 5.16 Opbrengst van de selectieprocedure met het gesprek resp. VOOR (onderste deel) en NA (bovenste deel van de figuur) de test: gemiddelde criteriumscores voor geselecteerde kandidaten
Noot. Voor de legenda: zie Figuur 15. Gesprek heeft voorspellende geldigheid 0,1, test voorspellende geldigheid 0,3. Gesprek als eerste selecteert 2 uit 8, test als eerste selecteert 4 uit 8. Beslissing valt op basis van score voor test en gesprek samen.
De voorspellende geldigheid van de selectie-instrumenten heeft geen gevolgen voor de mate waarin partijdigheid uitwerkt op de kansen voor vrouwen. Toch is voorspellende geldigheid het belangrijkste kenmerk van selectie-instrumenten. De effecten van voorspellende geldigheid moeten worden gezocht in de mate waarin geselecteerde kandidaten het in hun functie goed blijken te doen. Voor het vaststellen van die kwaliteit van functioneren kan een geschikt beoordelingsinstrument worden gebruikt. Bij de selectie is het de bedoeling de eventuele latere scores op dat beoordelingsinstrument te voorspellen: hoe beter die voorspelling, des te beter de opbrengst van de selectie. Figuur 16 laat het effect zien van doelmatiger gebruik van dezelfde instrumenten, in dit geval van gesprek en test: omkeren van de volgorde leidt tot aanzienlijke 'winst' door het beter benutten van het relatief meer valide psychologische onderzoek.
De winst in Figuur 16 is een stijging van verwachte criteriumscore van 0,12 standaarddeviatie. Deze stijging kan worden vertaald in financiële termen. Het vertrekpunt is het salaris van de aan te trekken functionaris, en het aantal jaren dat deze naar verwachting in dienst zal blijven. Veronderstel dat het bruto jaarsalaris Fl. 100.000 is. Criteriumscores kunnen nu worden omgezet naar guldens: een standaarddeviatie kan volgens een ruwe maar voorzichtige schatting gelijk worden gesteld aan 40 % van het jaarsalaris, in dit geval Fl. 40.000. [Er is discussie mogelijk over verschillende technieken en vooronderstellingen om tot dergelijke schattingen te komen, maar over de orde van grootte zoals hier gehanteerd bestaat geen verschil van mening. Zie bijv. Judiesch, Schmidt & Hunter (1993); deze auteurs komen op basis van empirisch onderzoek tot de conclusie dat de sleutel veelal ligt tussen 40% en 70%, in deze optiek is 40% een ondergrens.] Een winst van 0,1 standaarddeviatie levert een jaarlijkse opbrengst op van Fl. 4000. Veronderstel dat een directeur 10 jaar in dienst blijft, dan gaat het om een opbrengst van Fl. 40.000 die is te verkrijgen door de volgorde van gesprek en test om te keren. Voorzover het eerder inzetten van de test (psychologisch onderzoek) extra kosten met zich meebrengt (boven de kosten die worden uitgespaard door het gesprek later te plaatsen), moeten deze op de Fl. 40.0000 in mindering worden gebracht. Ook na aftrek van eventuele extra kosten blijft een verwachte verbetering van de selectieopbrengst over van ongeveer Fl. 30.000. Deze vertaling in economische termen kan abstract lijken: het gaat niet om de directeur van een bedrijf met winstoogmerk, maar van een school. Ook voor de school is het zo dat de kwaliteit van het onderwijs en het vermogen van de school om leerlingen aan te trekken mede afhangen van het functioneren van de directeur. Zou door het slecht functioneren van de directeur de school in zijn voortbestaan worden bedreigd, dan zijn daar aanzienlijke kosten mee gemoeid, naast het persoonlijke verlies dat leerlingen en leraren krijgen te verwerken.
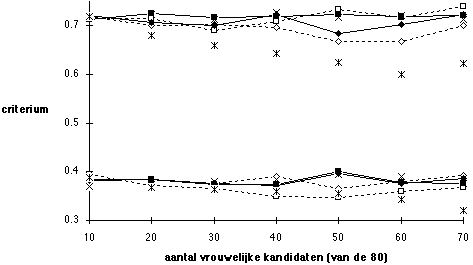
Figuur 5.17 Opbrengst van de selectieprocedure met het gesprek resp. VOOR (onderste deel) en NA (bovenste deel van de figuur) de test: gemiddelde criteriumscores voor geselecteerde kandidaten bij selectieverhouding 1 op 80
Noot. Voor de legenda: zie Figuur 15. Gesprek heeft voorspellende geldigheid 0,1, test voorspellende geldigheid 0,3. Gesprek als eerste selecteert 2 uit 80, test als eerste selecteert 4 uit 80. Beslissing valt op basis van score voor test en gesprek samen.
Het is instructief het rendement van intensievere werving hier eveneens te illustreren. Figuur 17 laat zien dat de selectieverhouding 1 op 80 een beter selectieresultaat geeft dan bij de selectieverhouding 1 op 8, op guldens gewaardeerd meer dan Fl. 40.000 wanneer de volgorde gesprek - test wordt gebruikt, meer dan Fl. 120.000 wanneer de omgekeerde volgorde test - gesprek wordt aangehouden (vergelijk met Figuur 16). De veronderstelling is echter dat de intensievere werving resulteert in 80 kandidaten die even goed gekwalificeerd zijn als de 8 kandidaten die zich bij een minder intensieve wervingscampagne aanmelden. Het is duidelijk dat een intensievere werving gericht op vrouwen het gunstige neveneffect kan hebben dat de groep behoorlijk gekwalificeerde sollicitanten groter wordt, waardoor de selectieprocedure een hoger rendement kan behalen. Tegenover de hogere opbrengst staan de extra kosten van de intensievere wervingscampagne, en de extra kosten omdat meer kandidaten moeten worden geselecteerd (meer gesprekken, meer psychologische onderzoeken).
De Figuren 16 en 17 laten ook zien dat de gevolgen van partijdigheid nauwelijks zijn af te meten aan criteriumscores. Alleen wanneer er een opeenstapeling is, of sterkere partijdigheid, zijn die gevolgen zichtbaar. Dit is jammer voor degenen die menen dat partijdigheid en discriminatie zichzelf straffen omdat daardoor de opbrengst van selectieprocedures vermindert: die opbrengst vermindert wel, maar nauwelijks merkbaar bij heel grote aantallen, en dus in het geheel niet merkbaar bij kleine.
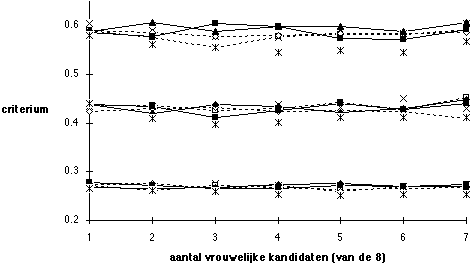
Figuur 5.18 Hoe hogere voorspellende geldigheid leidt tot hogere gemiddelde criteriumscore: beneden gesprek 0,1 en test 0,3; midden gesprek 0,2 en test 0,4; boven gesprek 0,3 en test 0,5
Noot. Voor de legenda: zie Figuur 15. Gesprek selecteert 2 uit 8. Beslissing valt op basis van score voor test en gesprek samen. Zie de tekst voor bespreking van maatregelen die tot deze verhogingen van voorspellende geldigheden zouden kunnen leiden.
Met Figuur 16 en 17 is gedemonstreerd hoe met het inzetten van het beste instrument voor de eerste selectiestap aanzienlijke winst in de opbrengst van de selectieprocedure valt te boeken, vergeleken met de situatie waarin het zwakste instrument, het gesprek, als eerste selectiedrempel wordt gebruikt. De verbeterde opbrengst komt voort uit een verhoging van de voorspellende geldigheid van de selectieprocedure. De doelmatigheid van de selectieprocedure kan dus ook worden verhoogd wanneer het lukt de voorspellende geldigheid van het gesprek en van de test te verhogen, door gebruik te maken van een goede functieanalyse, door voor het gesprek de methodiek van de selectiepsychologie toe te passen, en door specifieke instrumenten te ontwikkelen voor het psychologisch onderzoek. Veronderstel dat het lukt om voor beide instrumenten de voorspellende geldigheid in twee stappen te verhogen met telkens 0,1, dan laat Figuur 18 zien dat daarmee telkens 0,15 standaarddeviatie op het criterium wordt gewonnen, ofwel telkens circa Fl. 60.000. Figuur 18 geeft de resultaten waarbij eerst het gesprek, daarna de test wordt ingezet. Door in de procedure eerst een test met voorspellende geldigheid van 0,5 in te zetten, en daarna het gesprek met geldigheid 0,3, kan nog eens 0,1 standaarddeviatie worden gewonnen, ofwel Fl. 40.000 (hier niet afgebeeld).
De resultaten in Figuur 18 zijn cruciaal voor de beleidsafweging met betrekking tot de suggesties die door de panelleden zijn gedaan: verbeteringen in de voorspellende geldigheid in de orde van grootte van 0,1 door gebruik te maken van verantwoorde functieanalyses, door specifiek op deze functie ontwikkelde instrumenten voor het psychologisch onderzoek, en door bij het gesprek er op toe te zien dat daarbij de methodiek van de selectiepsychologie wordt toegepast, zijn zeker niet irreëel. Onderzoek heeft uitgewezen dat dergelijke verbeteringen haalbaar zijn wanneer enigszins slordige procedures en ongerichte instrumenten worden vervangen door meer gestructureerde die zijn gebaseerd op analyse van hetgeen in de functie aan kwalificaties wordt gevraagd. Bovendien brengen dergelijke verbeteringen met zich mee dat er minder gelegenheid voor het optreden van partijdigheid overblijft.
In een simulatiestudie is onderzocht welke de gevolgen kunnen zijn van eventuele partijdigheid bij het gesprek of de test in een selectieprocedure zoals deze doorgaans wordt gehanteerd bij de vervulling van vacatures voor directeur Primair Onderwijs. Ook is onderzocht welke gevolgen verbeteringen in de selectieprocedure kunnen hebben voor het rendement van de selectieprocedure. De gevolgde werkwijze bij deze simulaties is uitvoerig beschreven, omdat de simulaties een reële 'afbeelding' moeten zijn van de selectieprocedures zoals deze in werkelijkheid worden uitgevoerd; voor de technische en methodische aspecten van het gebruikte simulatieprogramma is verwezen naar Wilbrink (1990).
De simulatiestudie dwingt tot het operationeel definiëren van belangrijke begrippen als 'partijdigheid,' 'voorspellende geldigheid,' en het 'criterium.' Partijdigheid bij het waarderen van de gespreks- en testresultaten kan niet alleen gebeuren door één bepaalde groep stelselmatig hoger te waarderen dan een andere groep, maar ook door één groep stelselmatig meer gevarieerd te waarderen dan een andere. Het onderscheiden van deze laatste vorm van partijdigheid naar spreiding (zie Feingold, 1992) is belangrijk gebleken, omdat ook uit deze vorm van partijdigheid belangrijke verschillen in succeskansen kunnen voortvloeien. De voorspellende geldigheid van gesprek en test, alsook van de selectieprocedure in zijn geheel, is een cruciaal begrip in de selectiepsychologie (NIP, 1988). Juist omdat de voorspellende geldigheid zo'n belangrijke plaats inneemt in de theorie en in de praktijk van de personeelsselectie, zou het voor de hand liggen dat voorspellende geldigheid en partijdigheid met elkaar te maken hebben. De simulatiestudie heeft nog eens bevestigd wat op theoretische gronden reeds bekend was: voorspellende geldigheid en partijdigheid hebben niets met elkaar te maken. Dat betekent dat een selectieprocedure die partijdig is in dat opzicht niet kan worden verbeterd door te streven naar hogere voorspellende geldigheid. Iets anders is dat een goede functieanalyse effecten kan hebben op zowel partijdigheid als voorspellende geldigheid van gesprek en test. Hetzelfde geldt voor het structureren van het gesprek op basis van de methodiek van de selectiepsychologie: dat laat minder ruimte voor het optreden van partijdigheid en het leidt tot een verhoging van de voorspellende waarde van het gesprek. Ook het ontwikkelen van instrumenten specifiek voor de selectie van directeuren Primair Onderwijs kan leiden tot vermindering van mogelijk aanwezige partijdigheid, en tot verbetering van de voorspellende geldigheid van het psychologisch onderzoek (de 'test').
Een ander kwalitatief resultaat is dat de verhouding mannen - vrouwen bij de sollicitanten op zich geen of vrijwel geen invloed heeft op de gevolgen van eventuele partijdigheid. Het is dus niet zo dat zorgen voor een groter aandeel van vrouwen in de groep sollicitanten, bijvoorbeeld door intensiever te werven onder vrouwen, een dempende werking heeft op de gevolgen van eventuele partijdigheid in gesprek of test. Intensiveren van de werving onder vrouwen, en het verbeteren van het loopbaanbeleid voor vrouwelijke teamleden in het Primair Onderwijs, zijn op zich belangrijk om te bewerkstelligen dat vrouwen in redelijke verhouding door kunnen dringen tot het management van het Primair Onderwijs. Intensiever werven van vrouwen staat dus los van vraagstukken van partijdigheid in de selectieprocedure, eventuele partijdigheid zal daar op zich niet door verminderen. Intensiever werven van vrouwen kan wel leiden tot een hoger rendement van de selectieprocedure, en daarmee alleen al zichzelf dubbel en dwars terugverdienen. Het laatste effect is in de simulatiestudie niet expliciet onderzocht, wel is op een aantal plaatsen aangegeven dat scherpere selectieverhoudingen (een direct gevolg van grotere aantallen sollicitanten verkregen door intensiever werven) leiden tot een verhoogde opbrengst van de selectieprocedure.
De simulatiestudie leidt niet alleen tot kwalitatieve conclusies, maar ook tot kwantitatieve. De selectieprocedures voor directeuren Primair Onderwijs zijn behoorlijk selectief: doorgaans zijn er ongeveer acht kandidaten die op grond van een brievenselectie worden uitgenodigd voor een gesprek, waarna meestal alleen de door de commissie uitverkoren kandidaat nog aan een psychologisch onderzoek kan worden onderworpen. De simulaties gaan dan ook uit van een selectieverhouding van 1 op 8. Onder deze selectieverhouding blijken de bescheiden vormen van partijdigheid die in de simulaties zijn ingebouwd, te leiden tot tamelijk drastische verlaging van de succeskansen voor de benadeelde groep. Deze resultaten wijzen op de noodzaak een beleid te voeren dat partijdigheid waar dan ook in de selectieprocedure uitsluit. Of een dergelijk beleid succes heeft, valt in afzonderlijke selectieprocedures niet na te gaan omdat de aantallen kandidaten en een enkele benoeming daarvoor geen goed uitgangspunt vormen. Maar wat voor een enkele procedure niet kan, kan wel voor alle procedures gezamenlijk, bijvoorbeeld voor de meerdere honderden procedures die jaarlijks worden uitgevoerd. Wanneer de gemiddelde uitkomst is dat er relatief minder vrouwen worden benoemd dan er onder de serieuze kandidaten aanwezig waren, is dat een signaal dat er partijdigheid kan zijn. Volgens de operationele definitie van partijdigheid die in de simulatiestudie is gehanteerd, is iedere 'scheve' uitkomst een zeker teken van partijdigheid; in de praktijk is het niet onmogelijk dat er een goede verklaring voor scheefheid in resultaten is, een verklaring waar vrouwelijke kandidaten het als groep mee eens kunnen zijn. Een belangrijk kwantitatief resultaat met betrekking tot de gevolgen van partijdigheid is tenslotte nog dat partijdigheid slechts marginale gevolgen heeft voor het rendement van selectieprocedures. Het laatste betekent dat werkgevers niet vanzelf door de 'markt' zullen worden gestraft wanneer zij partijdig selecteren en concurrenten dat niet doen. Een reden te meer om het tegengaan van partijdigheid niet aan het eigen initiatief van alleen werkgevers over te laten.
Het verbeteren van de voorspellende geldigheid blijkt het rendement van de selectieprocedure belangrijk te kunnen verbeteren. In de analyses is een voorzichtige vertaling van criteriumscores naar financiële resultaten gehanteerd, waarin een verbetering in de verwachte criteriumscores van 0,1 standaarddeviatie gelijk staat aan een financiële meerwaarde van circa Fl. 40.000, in een enkele selectieprocedure. Verbeteringen door het hanteren van een goede functieanalyse zouden kunnen leiden tot een meerwaarde van circa Fl. 60.000. Eenzelfde meerwaarde kan ook nog eens worden gerealiseerd door zowel het gesprek strenger te structureren volgens de methodiek van de selectiepsychologie, als in het psychologisch onderzoek instrumenten in te zetten die specifiek voor deze selectie van directeuren Primair Onderwijs moeten worden ontworpen. Deze bedragen mogen echter niet zomaar worden vermenigvuldigd met het aantal selectieprocedures dat jaarlijks in ons land voor deze functie wordt gevoerd, omdat het reservoir van gekwalificeerde kandidaten maar beperkt is, en in beginsel alle werkgevers (besturen) uit datzelfde reservoir proberen de best gekwalificeerden in hun procedure te krijgen. Maar ook met deze kanttekening mag de conclusie worden getrokken dat bereikbare verbeteringen in deze selectieprocedures kunnen leiden tot een zeer aanzienlijk verhoogd rendement van de gezamenlijke selectieprocedures.
Simulatie is in dit onderzoek een nuttig instrument gebleken: door de simulatiestudie zijn op inzichtelijke wijze verbanden gelegd, en sommigen verbanden weerlegd, waar dat anders alleen via moeilijk navolgbare rekenkundige oefeningen zou moeten gebeuren. Het simulatieprogramma kan op dezelfde wijze worden ingezet om tal van andere varianten en veranderingen in selectieprocedures te onderzoeken, het is niet specifiek gebouwd voor de situatie dat er alleen een gesprek en een test is, en een selectieverhouding van 1 op 8.
Arvey, R. D., and Faley, R. H. (1988). Fairness in selecting employees. Amsterdam: Addison-Wesley.
Ashmore, R. D. (1990). Sex, gender, and the individual. In Pervin, L. A.: Handbook of personality; theory and research. New York: The Guilford Press. 486-526.
Born, M. Ph., Bleichrodt, N., & Van der Flier, H. (1987). Cross-cultural comparison of sex-related differences on intelligence tests. Journal of Cross-Cultural Psychology, 18, 283-314.
Feingold, A. (1992). Sex differences in variability in intellectual abilities: a new look at an old controversy. Review of Educational Research, 62, 61-84.
Hedges, L. V., & Friedman, L. (1993). Gender differences in variability in intellectual abilities: a reanalysis of Feingold's results. Review of Educational Research 63, 94-105.
Hunter, J. E., & Hunter, R. F. (1984). Validity and utility of alternative predictors of job performance. Psychological Bulletin, 96, 72-98.
Jensen, A. R. (1980). Bias in mental testing. London: Methuen.
Judiesch, M. K., Schmidt, F. L., & Hunter, J. E. (1993). Has the problem of judgment in utility analysis been solved? Journal of Applied Psychology, 78, 903-911.
NIP (1988). Richtlijnen voor ontwikkeling en gebruik van psychologische tests en studietoetsen. Amsterdam: Nederlands Instituut van Psychologen.
Press, W. H., Flannery, B. P., Teukolsky, S. A., & Vetterling, W. T. (1986). Numerical recipes. The art of scientific computing. Cambridge: Cambridge University Press.
Roe, R. A. (1983). Grondslagen der personeelsselektie. Assen: Van Gorcum.
Wilbrink, B. (1990). Complexe selectieprocedures simuleren op de computer. Amsterdam: SCO. (rapport 246) link pdf
Wilbrink, B., van Hoorn, W., van der Kamp, L.J.Th., & Algera, J. (1990). Selectie voor politie-officier. De toelating tot de Nederlandse Politie Academie. Amsterdam: SCO, 1990. (Rapport 245) link html
Beek, K. W. H. van, Koopmans, C. C., & van Praag, B. M. S. (1993). Discriminatie op de arbeidsmarkt? Economisch Statistische Berichten, 476-481.
Cudeck, R. (1993). A simple Gauss-Newton procedure for covariance structure analysis with high-level computer languages. Psychometrika, 58, 211-232.
Einhorn, & Bass (1971). Methodological considerations relevant to discrimination in employment testing. Psychological Bulletin, 75, 261-269.
Endler, J. A. (1986). Natural selection in the wild. Princeton University Press.
Flaugher (1978). The many definitions of test bias. American Psychologist, 33, 671- .
Govindarajulu, Z. (1988). Alternative methods for combining several test scores. Educational and Psychological Measurement, 48, 53-60.
Gross, & Su (1975). Defining a 'fair' or 'unbiased' selection model: a question of utilities. Journal of Applied Psychology, 60, 345-351.
Hartigan, J. A., & Wigdor, A. K. (Editors) (1989). Fairness in employment testing. Validity generalization, minority issues, and the General Aptitude Test Battery. Committee on the General Aptitude Test Battery; Commission on Behavioral and Social Sciences and Education; National Research Council. Washington, D.C.: National Academy Press.
Jensen, A. R. (1980). Bias in mental testing. New York: Free press.
Kaye, D. (1982). Statistical evidence of discrimination. Journal of the American Statistical Association, 77, 773-783.
Kok, Frank (1988). Vraagpartijdigheid. Methodologische verkenningen. Item bias Methodological Research. Amsterdam: SCO; Proefschrift UvA; SCO-rapport 88.
Law, S., & Myors, B. (1993). Cutoff scores that maximize the total utility of a selection program: comment on Martin and Raju's (1992) procedure. JAP, 78, 736-740.
Ledvinka, J., Markos, V. H., & Ladd, R. T. (1982). Long-range impact of 'fair selection' standards on minotity employment. Journal of Applied Psychology, 67, 18-36.
Linn, R. L. (1973). Fair test use in selection. Review of Educational Research, 43, 139-163.
Linn, R. L. (1976). In search of fair selection procedures. Journal of Educational Measurement, 13, 53-58.
Linn, R. L. (1984). Selection bias: multiple meanings. Journal of Educational Measurement, 21, 33-47.
Maesen de Sombreff, P.E.A.M. van der (1992). Het rendement van personeelsselectie. Proefschrift, R.U. Groningen.
Novick, M. R. (1980). Policy issues in fairness in testing. In Kamp, L. J. Th. van der, Langerak, W. F., & de Gruijter, D. N. M. (Editors). Psychometrics for educational debates. New York: Wiley 123-137.
Novick, M. R., & Ellis, D. D. (1977). Equal opportunity in educational and employment selection. American Psychologist, 32, 306-320.
Oppler, S. H., Campbell, J. P., Pulakos, E. D., & Borman, W .C. (1992). Three approaches to the investigation of subgroup bias in performance measurement: review, results, and conclusions. Journal of Applied Psychology, 77, 201-217.
Sackett, P. R., & Roth, L. (1996). Multi-stage selection strategies: a Monte Carlo investigation of effects on performance and minority hiring. Personnel Psychology, 49, 549-572.
abstract Schmitt, N., Coyle, B. W., & Mellon, P. M. (1978). Subgroup differences in predictor and criterion variances and differential validity. Journal of Applied Psychology, 63, 667-672.
Silva, Jay M., & Jacobs, R. R. (1993). Performance as a function of increased minority hiring. Journal of Applied Psychology, 78, 591-601.
Waller, N. G. (1993). Applied Psychological Measurement, 17, 73-100.
Soon-Hyung You and Eugene F. Stone-Romero (1996). Determinants of the quota-selection inequality phenomenon: Clarification of the basis for Gillet's (1991) findings. Educational and Psychological Measurement, 56, 585-599.
Yoder, J. D., & Kahn, A. S. (1993). Working toward an inclusive psychology of women. American Psychologist, 48, 846-850.
Sorel Cahan and Eyal Gamliel (2001). Prediction Bias and Selection Bias: An Empirical Analysis. Applied Measurement in Education, 14, 109-123.
Ik heb dit artikel niet gezien, maar geef wel het abstract:
Empirical examination of the relation between prediction bias and selection bias has been hampered by the lack of a valid definition of selection bias. In this article, we show that such a definition is possible in the special case of fixed-n selection, where the only reason for rejecting otherwise acceptable applicants is that their number exceeds the number of available places. Using the proposed definition, the empirical relation between prediction bias and selection bias with respect to prominent social groups is examined. The results indicate that although the 2 biases are related, the relation is not isomorphic: First, it is mediated by the selection ratio; second, for most selection ratios, its strength is only moderate. Thus, both the direction and the magnitude of prediction bias may be misleading as a basis for determining the corresponding direction and magnitude of selection bias. In particular, lack of prediction bias does not entail lack of selection bias. Hence, examination of selection bias with respect to social groups cannot rely only on empirical investigation of prediction bias. Rather, it calls for direct investigation of selection bias per se.
Jaap Dronkers (2005). Geef Ahmed een baan op niveau. De Volkskrant 27 augustus 2005.
"Hoogopgeleide allochtonen ondervinden serieuze discriminatie op de Nederlandse arbeidsmarkt. Dat is een gevaar voor de samenleving." Juist die hoog opgeleiden, die hoop hebben op een maatschappelijke positie, en daarin worden gefrustreerd. Ook hier, net als in het 1994 onderzoek, is die discriminatie moeilijk hard aan te tonen, hoewel statistische gegevens moeilijk anders te duiden zijn (het CBS duidt zijn cijfers in 2004 anders: het zouden leeftijdsverschillen zijn verschillen in arbeidsmarktpositie verklaren; Jaap ontkent dat op basis van eigen analyses van empirische gegevens).
Marieke van den Brink (2009). Behind the scenes of sciences. Gender practices in recruitment and selection of professors in the Netherlands. proefschrift RU Utrecht.
Wilfried de Corte (2005). The mean and variance of the selection differential after top-down selection from a mixture of normal samples. British Journal of Mathematical and Statistical Psychology, 58, 43-54. abstract
Alan Feingold (1995). The additive effects of differences in central tendency and variability are important in comparisons between groups. American Psychologist, 50, 5-12. abstract
![]() http://www.benwilbrink.nl/publicaties/94SeksepartijdigheidSVO.htm
http://www.benwilbrink.nl/publicaties/94SeksepartijdigheidSVO.htm